There are multiple options for loading JPEG files in the Windows desktop "stack". The application (see below) requires accessing the pixel data without displaying the image.
The application code is Native (not Managed) C++, consisting of a main EXE and a DLL. The image processing is implemented using CImg - The C++ Template Image Processing Toolkit (http://cimg.sourceforge.net). The pixel data loaded from the image is converted to the CImg internal format.
Libraries Measured
- JPEGLib V6 - as supplied by the original codebase
- JPEGLib V9b - http://www.ijg.org/files/
- LibJpeg-Turbo 1.4.2 - https://sourceforge.net/projects/libjpeg-turbo/files/1.4.2/
- GDI+ - comes with Windows
- WIC - comes with Windows
- WPF - comes with Windows
Results
Here are the results. The program was processing 1,057 Jpeg images, consuming 1.28GB of disk space, at an average of 1,272K per image. All were 24bpp and didn't cause any hiccups during loading. The smallest image is 260 by 400; the largest: 12,143 by 4,515.
These are external timings, average of three runs. All times in seconds.
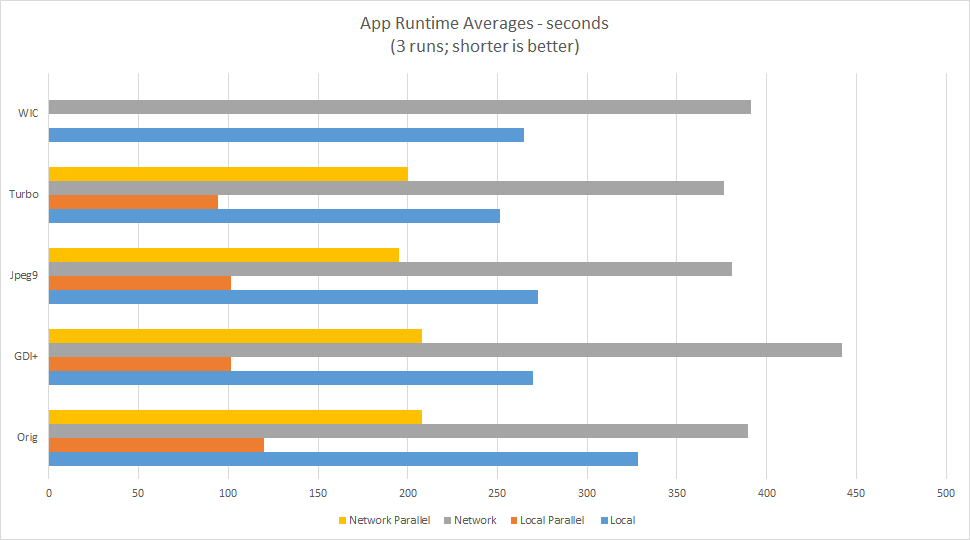
| Which | Local | Parallel | Network | Parallel |
| WIC | 264.78 | 0 | 391.45 | 0 |
| Turbo | 251.66 | 94.03 | 375.99 | 200.39 |
| Jpeg9 | 272.59 | 101.41 | 380.78 | 195.28 |
| GDI+ | 270.02 | 101.39 | 442.02 | 208.19 |
| Jpeg6 | 328.42 | 119.97 | 389.43 | 207.92 |
- Local: Loading the files from a local SSD.
- Network: Loading the files from a remote HD.
- Parallel: Using OpenMP to load/process files on separate threads.
Library Notes
LibJPEG 6 : CImg came with the LibJPEG 6 library, so this was tested as the "baseline". It is relatively simple to swap in LibJPEG 9 and LibJPEG-Turbo instead.
LibJPEG 9 : The latest release of the LibJPEG library.
LibJPEG-Turbo : The independently optimized version of LibJPEG.
GDI+ : The "old" way of loading images on Windows. Comparatively simple to use, caveat being some extra work required to deal with the Microsoft-specific pixel buffer layout. Has the benefit of handling more than just JPEG.
WIC : The "new" way of loading images on Windows. My implementation was not parallel friendly, so could not gather those numbers.
WPF : WPF is essentially a Managed wrapper around WIC. To use WPF, I chose to toggle on /clr and build essentially a Managed C++ application. Having to introduce Managed C++ destroyed performance, so WPF fell by the wayside very quickly.
Parallelism
As the application is CPU-bound, the next step was to use parallelism. The support for OpenMP is pretty straightforward to apply. The changes are:
#include "omp.h"- When iterating the file tree, gather the filenames into a list rather than process immediately.
- Process the list of filenames in a loop, along with the
#pragma omp parallel for - Enable OpenMP settings in the project.
This does add a dependency on vcomp120.dll.
The application happily maxed out all 8 cores on my system when running parallel. Using parallelism potentially cut the application runtime by more than half. Looking at the numbers, you can also see the choice of JPEG library makes little difference in the overall runtime.
Conclusion
In my testing, LibJpeg-Turbo and JPEGLib V9b are tied, especially for my typical scenario; JPEGLib V9b may have a tiny edge. When running in parallel, GDI+ is only a few seconds behind for 1,000 images. The ability to handle more than just JPEGs makes GDI+ a strong contender.
For this CPU-bound application, parallel computing is the big winner.
The Application
The application under test is an implementation of the "perceptual hash" (phash). Specifically, a Windows port of v0.9.4 of the open source perceptual hash library (www.phash.org). pHash is a perceptual hashing library that allows you to find similar media files without them having to be bit-for-bit identical.
The code used to convert the Windows bitmap buffer to CImg is from Ken Earle - http://www.dewtell.com/code/cpp/cimggdip.htm